Table Of Content
Ok, with this scenario in mind, let's consider three cases that are relevant and each case requires a different model to analyze. The cases are determined by whether or not the blocking factors are the same or different across the replicated squares. The treatments are going to be the same but the question is whether the levels of the blocking factors remain the same. We can test for row and column effects, but our focus of interest in a Latin square design is on the treatments. Just as in RCBD, the row and column factors are included to reduce the error variation but are not typically of interest. And, depending on how we've conducted the experiment they often haven't been randomized in a way that allows us to make any reliable inference from those tests.
ANOVA and Mixed Models:

Just like any other factor not included in the design you hope it is not important or you would have included it into the experiment in the first place. In this factory you have four machines and four operators to conduct your experiment. Use the animation below to see how this example of a typical treatment schedule pans out. Before high-speed computing, data imputation was often done because the ANOVA computations are more readily done using a balanced design.
When to use a randomized block design?
When there are only two treatments, this is known as a “matched pairs” design. The whole experiment consists of “N” such blocks where N is sample size. A two-way analysis of variance without interaction is used to analyse the results.
2 Power for randomized complete block design
We do not have observations in all combinations of rows, columns, and treatments since the design is based on the Latin square. We want to account for all three of the blocking factor sources of variation, and remove each of these sources of error from the experiment. The Greek letters each occur one time with each of the Latin letters. A Graeco-Latin square is orthogonal between rows, columns, Latin letters and Greek letters. In this case, we have different levels of both the row and the column factors. Again, in our factory scenario, we would have different machines and different operators in the three replicates.
Sometimes several sources of variation are combined to define the block, so the block becomes an aggregate variable. Consider a scenario where we want to test various subjects with different treatments. A block is characterized by a set of homogeneous plots or a set of similar experimental units. In agriculture a typical block is a set of contiguous plots of land under the assumption that fertility, moisture, weather, will all be similar, and thus the plots are homogeneous. First the individual observational units are split into blocks of observational units that have similar values for the key variables that you want to balance over.
You are studying how bread dough and baking temperature affect the tastiness of bread. And let's say you're purchasing packaged bread dough from some food company rather than mixing it yourself. Here is a concise answer.A lot of details and examples might be found in most documents treating the design of experiments; especially in agronomy. Switch them around...now first fit treatments and then the blocks.
Lesson 4: Blocking
We cannot fit a more complex model, includinginteraction effects, here because we do not have the corresponding replicates. By randomly assigning individuals to either the new diet or the standard diet, researchers can maximize the chances that the overall level of discipline of individuals between the two groups is roughly equal. Often, the researcher is not interested in the block effect per se, but he only wants to account for the variability in response between blocks. Of note, the block effect is typically considered as a random effect. Finally, if you expect the 'treatment effect' to differ from block to block, then interactions should be considered. Note that the least squares means for treatments when using PROC Mixed, correspond to the combined intra- and inter-block estimates of the treatment effects.
Here are the main steps you need to take in order to implement blocking in your experimental design. Each paper was searched for the words “random”, “experiment”, “statistical”, “matched” and other words necessary to understand how the experiments had been designed. The discipline and type of animals which had been used (wild-type, mutant, or genetically modified) was also noted. The aim was to assess the design of the experiments, not the quality of research. In most pre-clinical experiments inter-individual variation can be minimised by choosing animals which are similar in age and/or weight. They will have been maintained in the same animal house and should be free of infectious disease.
2 Wrong analysis
In “Completely randomized” (CR) and “Randomised block” (RB) experimental designs, both the assignment of treatments to experimental subjects and the order in which the experiment is done, are randomly determined. These designs have been used successfully in agricultural and industrial research and in clinical trials for nearly a century without excessive levels of irreproducibility. They must also be used in pre-clinical research if the excessive level of irreproducibility is to be eliminated.
Analysis of Mutants Suggests Kamin Blocking in C. elegans is Due to Interference with Memory Recall Rather than ... - Nature.com
Analysis of Mutants Suggests Kamin Blocking in C. elegans is Due to Interference with Memory Recall Rather than ....
Posted: Wed, 20 Feb 2019 08:00:00 GMT [source]
These can also be used in pre-clinical research in appropriate situations13, although they are not discussed here. For example, suppose researchers want to understand the effect that a new diet has on weight less. The explanatory variable is the new diet and the response variable is the amount of weight loss. A farmer possesses five plots of land where he wishes to cultivate corn. He wants to run an experiment since he has two kinds of corn and two types of fertilizer.
It would reduce the overall effect of that treatment, and the estimated treatment mean would be biased. Generally the unexplained error in the model will be larger, and therefore the test of the treatment effect less powerful. Here we have four blocks and within each of these blocks is a random assignment of the tips within each block. Back to the hardness testing example, the experimenter may very well want to test the tips across specimens of various hardness levels. To conduct this experiment as a RCBD, we assign all 4 tips to each specimen.
This leads to a waste of scientific resources with excessive numbers of laboratory animals being subjected to pain and distress3. There is a considerable body of literature on its possible causes4,5,6,7, but failure by scientists to use named experimental designs described in textbooks needs further discussion. We consider an example which is adapted from Venables and Ripley (2002), the original source isYates (1935) (we will see the full data set in Section 7.3). Atsix different locations (factor block), three plots of land were available.Three varieties of oat (factor variety with levels Golden.rain, Marvellousand Victory) were randomized to them, individually per location. Gender is a common nuisance variable to use as a blocking factor in experiments since males and females tend to respond differently to a wide variety of treatments. A 3 × 3 Latin square would allow us to have each treatment occur in each time period.
For an odd number of treatments, e.g. 3, 5, 7, etc., it requires two orthogonal Latin squares in order to achieve this level of balance. For even number of treatments, 4, 6, etc., you can accomplish this with a single square. This form of balance is denoted balanced for carryover (or residual) effects.
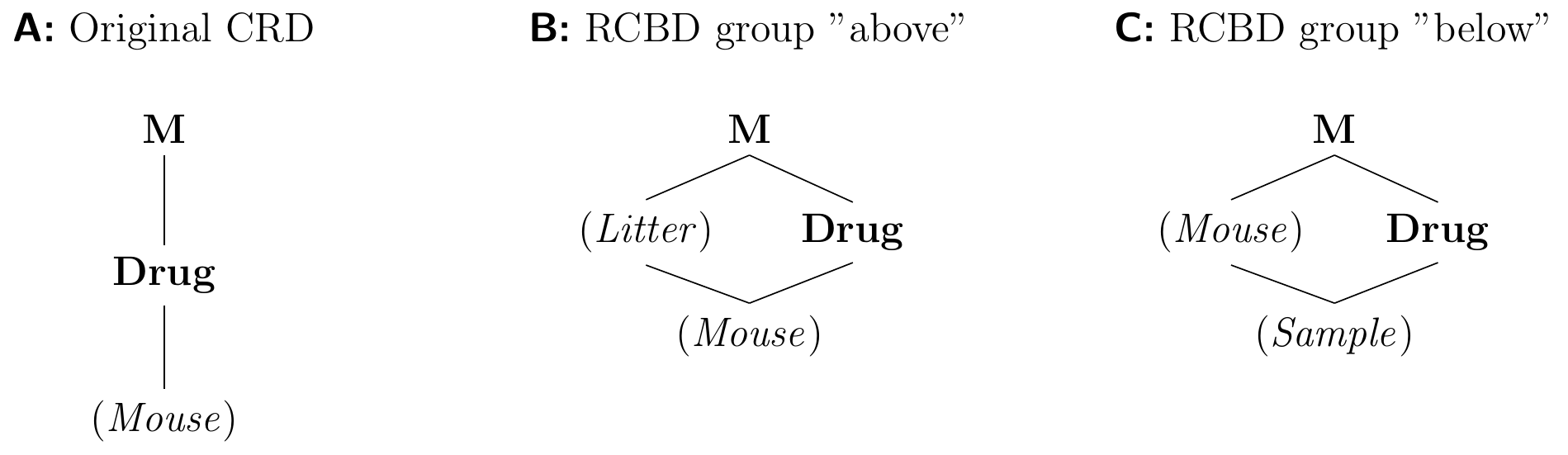
Results from several litters are then combined in the analysis16. Typical block factors are location (see example above), day (if an experiment isrun on multiple days), machine operator (if different operators are needed forthe experiment), subjects, etc. Depending on the nature of the experiment, it’s also possible to use several blocking factors at once. However, in practice only one or two are typically used since more blocking factors requires larger sample sizes to derive significant results. The Design Structure has one factor (oven run, Run), and the Treatment Structure two factors (Recipe and Temperature).
Note, that the power is indeed much larger for the randomized complete block design. A survey of published papers using mice or rats was used to assess the use of CR, RB, or other named experimental designs. PubMed Central is a collection of several million full-text pre-clinical scientific papers that can be searched for specific English words. The first fifty of these had been published between 2014 and 2020. They were not in any obvious identification number or date order.
Here is a plot of the least squares means for Yield with the missing data, not very different. Why is it important to make sure that the number of soccer players running on turf fields and grass fields is similar across different treatment groups? Identify potential factors that are not the primary focus of the study but could introduce variability. In other words, when the error term is inflated, the percentage of variability explained by the statistical model diminishes. Therefore, the model becomes a less accurate representation of reality.








No comments:
Post a Comment